- Research
- Open access
- Published:
CMRF: analyzing differential gene regulation in two group perturbation experiments
BMC Genomics volume 13, Article number: S2 (2012)
Abstract
Background
Microarray experiments often measure expressions of genes taken from sample tissues in the presence of external perturbations such as medication, radiation, or disease. The external perturbation can change the expressions of some genes directly or indirectly through gene interaction network. In this paper, we focus on an important class of such microarray experiments that inherently have two groups of tissue samples. When such different groups exist, the changes in expressions for some of the genes after the perturbation can be different between the two groups. It is not only important to identify the genes that respond differently across the two groups, but also to mine the reason behind this differential response. In this paper, we aim to identify the cause of this differential behavior of genes, whether because of the perturbation or due to interactions with other genes.
Results
We propose a new probabilistic Bayesian method CMRF based on Markov Random Field to identify such genes. CMRF leverages the information about gene interactions as the prior of the model. We compare the accuracy of CMRF with SSEM and Student's t test and our old method SMRF on semi-synthetic dataset generated from microarray data. CMRF obtains high accuracy and outperforms all the other three methods. We also conduct a statistical significance test using a parametric noise based experiment to evaluate the accuracy of our method. In this experiment, CMRF generates significant regions of confidence for various parameter settings.
Conclusions
In this paper, we solved the problem of finding primarily differentially regulated genes in the presence of external perturbations when the data is sampled from two groups. The probabilistic Bayesian method CMRF based on Markov Random Field incorporates dependency structure of the gene networks as the prior to the model. Experimental results on synthetic and real datasets demonstrated the superiority of CMRF compared to other simple techniques.
Background
Microarray experiments often measure expressions of genes taken from sample tissues in the presence of external perturbations such as medication, radiation, or disease [1, 2]. Typically in such experiments, gene expressions are measured before and after the application of external perturbation, and are called control data and non-control data, respectively. In this paper, we focus on an important class of such microarray experiments that inherently have two groups of tissue samples. Different groups in a microarray measurement can exist in many different ways. For instance, samples can be taken from members of multiple closely related species (e.g. rat versus mouse). Within the same species there can be subgroups with different phenotypes (e.g. African American versus Caucasian American). Another example is when the samples have already been through several alternative external perturbations (e.g. fasting and not fasting). When such different groups exist, it is not only important to observe overall changes in gene expression, but also to observe how different groups respond to the external perturbation. For example, Taylor et al. applied medications on 36 Caucasian American and 33 African American patients infected with Hepatitis C [3]. Gene expressions were collected before and after the medication.
In a perturbation experiment, some of the genes respond by noticeably changing their expression values between the control and non-control data. Genes that change their expressions in a statistically significant way are referred to as differentially expressed (DE), while those that do not, are referred to as equally expressed (EE) genes. In the context of two groups, we refer to a gene that has the same state in both the groups, i.e. either DE or EE for both the groups, as equally regulated (ER) gene. On the contrary, if a gene is DE in one group and EE in the other, we denote it as differentially regulated (DR).
Genes for any organism typically interact with each other via regulatory and signaling networks. For simplicity, we will refer to them as gene networks for the rest of this paper. A small portion of an example gene network can be seen in Figure 1.

A sample gene regulatory network. Illustration of the impact of a hypothetical external perturbation on a small portion of the Pancreatic Cancer pathway. The pathway is taken from the KEGG database. The solid rectangles denote the genes affected directly by perturbation, the dashed rectangles indicate genes secondarily affected through the networks. The dotted rectangles denote the genes without any change in expression. → implies activation and ⊣ implies inhibition. In this figure, genes K-Ras, Raf and Cob42Roc are primarily affected and MEK, Ral and RalGDS are secondarily affected through interactions.
Once an external perturbation is applied, a gene can be DE in one of the two ways - as a direct effect of the perturbation or via interaction with other DE genes through gene networks. We denote a gene as primarily affected DE, if it is DE due to the external perturbation. Similarly, a gene is secondarily affected DE, if it is DE due to another gene in the gene network. Figure 1 shows the state of the genes in the Pancreatic Cancer pathway after a hypothetical external perturbation is applied. In this figure, genes K-Ras, Raf and Cob42Roc are primarily affected and MEK, Ral and RalGDS are secondarily affected through interactions.
Recall that for a gene to be DR, it has to be EE in one group and DE in another group. For such a gene, if it happens to be DE in one group because of the external perturbation, we call it as primarily differentially regulated (PDR) gene. When it is DE in one group because of the interaction with other DE genes in the gene networks, we will refer to it by secondarily differentially regulated (SDR) gene. In this paper, we consider the problem of identifying the PDR genes in a given set of control and non-control gene expressions from two groups of samples.
Existing methods to identify the primarily affected DE genes using association analysis techniques [4, 5], haplo-insufficiency profiling [6–8] and chemical-genetic interaction mapping [9] are limited to applications where additional information such as fitness based assays of drug response or a library of genetic mutants is available. Bernardo et al. suggested a regression based approach named MNI that assumes that the internal genetic interactions are offset by the external perturbation [10]. It estimates gene-gene interaction coefficients from the control data and uses them to predict the target genes in the non-control data. Cosgrove et. al. proposed a method named SSEM that is similar to MNI [11]. SSEM models the effect of perturbation by an explicit change of gene expression from that of the unperturbed state.
We have also developed a method to detect the primarily and secondarily affected genes in perturbation experiments with a single data group [12]. We will call this method SMRF (single MRF) in the rest of this paper for it applies MRF on single group datasets. In that paper we developed a Bayesian probabilistic method based on Markov Random Field that leverages the information from gene networks as the prior belief of the model.
Though these methods analyze primary and secondary effects of perturbation on gene expressions, they are not directly applicable for multi-group perturbation experiments.
Several recent studies aim to identify DE genes in multiple groups of data points. maSigPro is a two stage regression based method that identifies genes that demonstrate differential gene expression profiles across multiple experimental groups [13]. Hong et al. proposed a functional hierarchical model for detecting temporally differentially expressed genes between two experimental conditions [14]. They modeled gene expressions by basis function expansion and estimate the parameters using a Monte Carlo EM algorithm. Tai et al. ranked DE genes using data from replicated microarray time course experiments, where there are multiple biological conditions [15]. They derived a multisample multivariate empirical Bayes statistic for ranking genes. Angelini et al. proposed a Bayesian method for detecting temporally DE genes between two experimental conditions [16]. Deun et al. developed a Bayesian method to find the genes that are differentially expressed in a single tissue or condition over multiple tissues or conditions [17]. All these methods identify differentially expressed genes in multiple groups. However, none of these methods analyzed the primary and secondary effects in a two group perturbation experiment. In this paper, we develop a method to solve this problem.
Our approach
In this paper, we propose a new probabilistic Bayesian method CMRF to find the PDR genes in two group perturbation experiment dataset as defined above. We call this method CMRF (Comparative MRF) for it applies MRF on two groups of data for comparison purpose. Our Bayesian method incorporates information about relationship from gene networks as prior beliefs. We consider the gene network as a directed graph where each node represents a gene, and a directed edge from gene g i to gene g j represents a genetic interaction (e.g g i activates or inhibits g j ). We define two genes as neighbors of each other if they share a directed edge. For example, in Figure 1, genes K-Ras and Raf are neighbors as K-Raf activates Ras. We also classify a neighbor as incoming or outgoing, if it is at the start or at the end of the directed edge respectively. In Figure 1, Raf is an incoming neighbor of MEK and MEK is an outgoing neighbor of Raf. When the expression level of a gene is altered, it can affect some of its outgoing neighbors. Thus, the gene expression can change due to external perturbation or because of one or more of the affected incoming neighbors.
We represent the external perturbation by a hypothetical gene (i.e. metagene) g0 in the gene network. We add an edge from the metagene to all the other genes because the external perturbation has the potential to affect all the other genes. So, g0 is an incoming neighbor to all the other genes. We call the resulting network the extended gene network. CMRF estimates the probability that a gene g j is DR due to an alteration in the activity of gene if there is an edge from g i to g j in the extended network. We use a Bayesian model in our solution with the help of Markov Random Field (MRF) [18] to capture the dependency between the genes in the extended gene network. We define feature functions that encapsulate the domain knowledge available from gene networks and gene expression data. CMRF optimizes the joint posterior distribution over the random variables in the MRF using Iterated Conditional Modes (ICM) [19]. The optimization provides the state of the genes, the regulation of the genes and the probabilistic estimate of pairwise interactions between the genes including the metagene. Given this, we can rank the genes according to the data likelihood that a gene is DR because of the metagene g0, and obtain a list of possible PDR genes.
Figure 2 illustrates different components of CMRF and the connectivity between them. Note that, (C) corresponds to the Bayesian prior based on MRF.

Illustration of different components of CMRF and connectivity between them. (A) obtains an initial estimates of state variables using Student's t test. (B) estimates parameters in a way that maximizes data likelihood. (C) estimates parameters in order to maximize prior density. Both (B) and (C) use a global optimization technique called Differential Evolution. (D) employs Iterated Conditional Modes to maximize the pseudo-likelihood. (B), (C) and (D) consist of an alternating optimization technique. These three steps (B), (C) and (D) are repeated till the algorithm meets a criteria for completion. Finally, once the optimization is complete, the DR genes are sorted in decreasing order of their likelihood with respect to the metagene g0. The genes at the top of the list are declared PDR.
We compare the accuracy of CMRF with that of SSEM and Students t test on semi-synthetic dataset generated from microarray data in Cosgrove et al [11]. We also compare CMRF with our old method SMRF that we developed to identify the primarily affected DE genes in a single group perturbation data [12]. CMRF obtains high accuracy and outperforms all the other three methods. Also, we conduct a statistical significance test using a parametric noise based experiment to evaluate the accuracy of CMRF. In this experiment our model demonstrates reasonable confidence regions for various values of the parameters.
The rest of the paper is organized as follows. Section Results and discussion presents the results of our experiments. Section Methods describes our methods in detail. Section Conclusions concludes our discussion.
Results and discussion
In this section we discuss the experiments we conducted to evaluate the quality of CMRF. We implemented CMRF in MATLAB and Java. We obtained the code for Differential Evolution from http://www.icsi.berkeley.edu/~storn/code.html. We compared CMRF with SSEM as SSEM is one of the most recent methods that considers identifying primarily affected genes in a perturbation experiments [11].
We obtained SSEM from http://gardnerlab.bu.edu/SSEMLasso. We executed our code on a Quad-Core AMD Opteron 2 Ghz workstation with 32 GB of memory.
Dataset
We used four different sets of data to conduct the experiments in this paper.
-
Dataset 1. The first dataset was collected by Smirnov et al. [20]. This dataset was generated using 10 Gy ionizing radiation over immortalized B cells obtained from 155 members of 15 Centre d'tude du Polymorphisme Humain (CEPH) Utah pedigrees [21]. Microarray snapshots were obtained before (at zeroth hour) and after (at second and sixth hours) the application of radiation.
-
Dataset 2. The second dataset corresponds to a drug response experiment conducted by Taylor et al [3]. Medications were applied on 36 Caucasian American and 33 African American patients infected with Hepatitis C. Gene expressions were collected before the medication was started and at 1, 2, 7, 14, 28 days after the medication was administered.
Both dataset 1 and 2 are microarray time series data with more than two time points. We adapted these two time series data two create control and non-control data suitable for our experiments. We used the data before perturbation as control data. For the non-control data we calculated the expected expression of a gene at each points after the perturbation. We selected the one with highest absolute difference from the expected expression of control data for that gene.
-
Dataset 3. We created dataset 3 using dataset 1. We used the control group of dataset 1 as the control group of dataset 3. Then, we changed the expression values of some of the randomly selected genes to model the primary effect of external perturbation. From that perturbed dataset, we simulated the secondary effects using the sigmoid method described in Garg et al. [22]. We denote the parameter for primary perturbation effect by deviation. Deviation is the ratio of the change of expression value Δx of a gene to its original expression value x (i.e. ) which is normalized between zero and one. We tuned the other parameters of the method to create a meaningful dataset as follows; alpha = 1, β = 0.01, k ac = 1.0, k in = 1, h = 0.1.
-
Dataset 4. We create this dataset from dataset 1 in two steps as follows.
-
- Selection of genes. In order to carry out experiments on larger scale data with known PDR genes, we generated data in the presence of a hypothetical perturbation from the real datasets as follows. We first select three sets of genes. Each set consists of some primarily affected genes and a higher number of secondarily affected genes. Here, we describe how we construct each of the three sets of affected genes. We first select a random gene from the network and label it as a primarily affected DE gene. We then traverse its outgoing neighbors in a breadth first search manner. As we visit a gene during traversal, we label it as a secondarily affected DE gene with a probability of 1 − (1 − q)η, where η is the number of incoming DE neighbors. Here q is the probability that a gene is DE due to a DE predecessor (0.4 in our experiments). We repeat these steps to create the desired number of primarily affected genes.
After we obtain the three set of genes, we assign one set to both D A and D B groups. We assign the other two sets of genes to different groups. These two set of genes are differentially regulated as they are affected in only one group and not in the other. The three groups can contain different number of primarily and secondarily affected genes. We call these three sets of genes as primarily differentially regulated, secondarily differentially regulated and equally regulated genes.
-
Generation of gene expression. Once we identify these three sets of genes in the two groups, we create control and non-control data for D A and D B over N samples. We use the control part of the real dataset in Smirnov et al. as the control part of our synthetic dataset in both D A and D B [20]. To generate the non-control dataset, we traverse each of the genes that participate in the gene networks. Consider a gene g i with mean and standard deviation of expression in the control dataset given by µ i and σ i respectively.
If the gene is EE we generate its non-control data points from the a normal distribution given by the parameters (µ i , ). If the gene is DE, we use the same variance but different mean as that of the control group. For the primarily and secondarily affected genes we use µ i ± d p and µ i ± d s respectively, where d p >d s .
-
To summarize, we used the same variance in the non-control group as that in the control group. However, for an affected gene we changed the value of the mean in the non-control group from that in the control group. For a primarily affected gene we applied a higher deviation of mean than that of the secondarily affected genes.
Regulatory networks
We collected 24,663 genetic interactions from the 105 regulatory and signaling pathways of KEGG database [23]. Overall 2,335 genes belong to at least one pathway in KEGG. In our model, we considered only the genes that take part in the gene networks.
Comparison to other methods
Our method provides us a list of differentially regulated genes. We sort the list of those genes as follows. Consider a DR gene g i , which is DE in D A and EE in D B . We calculate the likelihood of being EE in D A and DE in D B for that gene. We can interpret this step as the probability of being DR, but in a reverse way. We could instead use the probability that the gene is DE in D A and EE in D B . However, according to our observation, the earlier metric provides a much better accuracy. We sort all the DR genes with increasing order of that likelihood.
As per our knowledge, no other method exists that differentiates between the primary and secondary effects in a two-group perturbation experiment. There exist some studies in identifying primarily affected genes in single group datasets. We compared the accuracy of CMRF to three such methods namely, SMRF, Student's t test and SSEM.
Experimental setup
Given an input dataset, using each of the four methods, we ranked all the genes. Highly ranked genes have higher chance of being a PDR according to each method. However, as other three methods are not tailored to solve this problem, we created separate ranking on D A and D B . Then, out of those two ranks, we created a unified rank of differentially regulated genes. We shall elaborate on this unified rank creation later. We, first, explain how we create ranks on individual groups D A and D B for other three methods.
-
SMRF. We apply the SMRF to each group separately and obtain a set of differentially expressed genes. We sort the genes in decreasing order of joint likelihood with the metagene. A higher joint likelihood implies a higher chance of being primarily affected.
-
SSEM. We train SSEM on the control dataset, where it learns the correlation between the genes. We test SSEM on the non-control dataset of each group, where it produces a rank for each single data point.
-
Student's t test. We use the function called ttest2 from MATLAB. We apply it on every individual gene, where it takes control and non-control dataset as input and produces a p-value as output. We assume that the null hypothesis corresponds that the gene is EE. So a substantially lower p-value implies a higher chance of being primarily affected. We perform the test on all the genes and rank them according the increasing order of p-values.
Now we describe how we create an unified ranking of differentially regulated genes for these three methods. We denote the ranks from data group D A and D B by R A and R B respectively. The unified rank is defined by R U . We denote the number of genes in each rank to be ω A and ω B respectively. We scan both the ranks simultaneously from first position to ω = min(ω A , ω B ). While scanning at the kth position, we denote the equally regulated set obtained till that position by Λ k = R A (1: k) ∩ R B (1: k). We include R T (k) to the unified rank R U if R T (k) ∉ Λ k , T ∈ {A, B}. For SSEM we obtain a separate R U for each data point. We average the accuracies over all these ranks.
Results
In this experiment we used dataset 3, that we have just described. To observe the accuracy of CMRF at varying degree of difficulties, we conducted experiments with four different values of deviation, namely, {0.5, 0.6, 0.7, 0.8}. However, we discuss only two of them in this paper (see Figure 3) since for other two parameters the results are similar. The results we discuss correspond to the cases when deviation = {0.6, 0.8}.

Comparison of CMRF with three other methods. Comparison of our method CMRF to SMRF, SSEM and t-test. The number of primarily differentially affected genes is 40. The values for deviation (maximum perturbation to the PDR genes) are 0.6 and 0.8. The figures indicate that CMRF outperforms SMRF, SSEM and t-test.
Figures 3(a) and 3(b) show the sensitivity of the four methods with the two deviation settings. The former one corresponds to the computationally harder case as the difference between the non-control groups of primarily and secondarily affected genes is small. As the deviation increases identifying primarily affected genes becomes easier. Form the figure, we observe that CMRF is significantly more accurate than the other three methods for all datasets consistently. It reaches almost 50% sensitivity (i.e., it can find around 15-18 primarily affected genes out of 30) in the top 50 ranked genes, when the deviation is 0.6. On the other hand, its achieves a sensitivity of 0.6 when the deviation is 0.8. We obtained similar results for other deviations, which we do not discuss here. The method in SMRF reaches to 30% and 40% accuracy, however at a slower pace. The t-test reaches around 25% and 30% sensitivity at ranking position 50 for these two cases respectively. SSEM's sensitivity is below 0.1 for all experiments even within the top 50 positions.
We believe that there are three major factors for the success of our method over the other competing methods. First, the other methods do not simultaneously handle two groups of datasets and are not able to generate an unified ranking of differentially regulated genes. CMRF encompasses both groups in a single model and probabilistically determines the PDR genes. Hence, it is more shielded against the false positives introduced during the unification of ranking. Second, CMRF can successfully incorporate the gene interactions using MRFs while others ignore this information. Finally, in real perturbation experiments, multiple genes are often primarily affected. CMRF is capable of dealing with both large and small number of primarily affected genes, while performances of other methods deteriorate as the number of primarily affected genes grows. Thus, we conclude that our method is more suitable for real perturbation experiments.
Statistical significance experiment
The experiments in the last section enable us to compare the accuracy of CMRF with that of the other methods on synthetic datasets. We also wanted to evaluate the accuracy of CMRF on real dataset. However, we do not have any gold standard available that enlists true set of PDR genes. Hence, we conducted a set of statistical significance experiments to estimate the confidence of our accuracy. Specifically, we obtained the control data from a real dataset, perturbed it in a controlled way for a number of genes. We calculated the likelihood probabilities of those genes and created a distribution. We repeated this process with varying amount of perturbation. Finally, we executed CMRF on a real dataset and analyzed the result.
Results
We obtained the real dataset from drug response experiment conducted by Taylor et al [3], which is actually dataset 2. Apart from this real dataset, we create different versions of dataset 4 by varying d p as {0.1, 0.2, 0.3,..., 3.0}. If d p > 1.1, we set d s to 1, otherwise d s = 0.5 × d p . Thus, we have 30 synthetic datasets in total. In every dataset, we fix the number of primarily and secondarily differentially regulated genes to 50 and 172 respectively. To decide whether a gene g i is DR, when g i is DE in D A and EE in D B , we define a null-hypothesis H0i: g i is DR, but in the reverse way, i.e. g i is EE in D A and DE in D B . We calculate the likelihood of being EE in D A and DE in D B for that gene, as described. For gene g i , we denote the log likelihood of accepting H0iby LL i . In every dataset, we create a box plot of the 50 LL i values, as the number of DR genes in each dataset is 50. A lower value LL i indicates that g i has a higher probability of being differentially regulated.
Figure 4 illustrates the statistical significance of the experiments over the datasets with d p = 1.2 to 2.0. The box plot demonstrates a relationship between the P-value and d p . A higher value of d p indicates a lower P-value and hence, a high chance of being PDR. We also observe that the variance of P-value increases with the increase of d p .

Illustration of statistical significance test. Illustration of the statistical significance test. Box plot demonstrates the P-value of null hypothesis of the DR genes over synthetic dataset. From the plot we clearly conclude that a higher gap between the control and non-control group of a DR gene leads to a lower P-value. The genes with a lower P-value have a higher chance of being primarily differentially regulated.
We also executed CMRF on the real datasets without any modification. Interestingly, on the real dataset from Taylor et al. [3] (dataset 2), we did not obtain any genes as differentially regulated. A careful observation concludes that when both the number of data points and the gap d p (i.e. the signal to noise ratio) is low, the coefficients γ6 and γ7 in the prior density become strong and all genes are identified as equally regulated. However, when either the number of data points or d p is significantly high, the data can overcome the prior. In the current real dataset, the number of data points is only 33 and the gaps between the control and non-control group were less than 1.2 × σ. As a result, CMRF identifies no differentially regulated genes in the dataset. Thus, we can conclude that either there is not much difference between the two groups in the real data, or the data does not contain enough data points, so that our model can highlight difference between the two groups.
In Figure 4 we present the results for d p = 1.2 to 2.0. Note, that for d p < 1.2 × σ our model did not identify any DR genes. Here also, we attribute a similar reason for not finding any DR genes as both d p and the number of data points are small. On the other hand, in Section Comparison to other methods, when we execute CMRF on synthetic datasets with 155 data points we were able to identify a substantial number of true PDR genes even with d p = 0.02 × σ. To substantiate our conclusion that there exists little difference between the two groups in the real dataset, we conducted a set of permutation tests. We shuffled the two original groups to create new sets of data. We repeated this process for a number of times (40 in the present experiment) and executed CMRF on each of them. For every derived dataset, CMRF did not find any DR genes. Hence, this experiment bolsters the claim that there are no DR genes in the original real data.
An interesting question can be raised is that "is there indeed no DR genes in the real dataset from Taylor et al. [3]?" Another similar question can be "will our method be able to detect DR and PDR genes from similar other real datasets?" We believe that CMRF requires a bigger dataset for DR and PDR genes to be discovered. For example, CMRF is able to identify the DR and PDR genes from the synthetic dataset that contains substantially higher number of data points than that of the real dataset. Since the difference between control and non-control groups of a DE gene is small compared to the variance of the data points, it is difficult to detect that subtle effect of perturbation with a small dataset. For a small dataset, the prior due to third hypothesis becomes strong and the two corresponding parameters γ6 and γ7 assumes extreme values. Thus the support from data is not sufficient to overcome the prior and hence, the method is not able to identify the DR and PDR genes. There are two solutions to overcome this problem. First of them is to employ a bigger dataset. With the advancement of comparatively inexpensive and high throughput technologies bigger dataset are increasingly common nowadays. From that perspective, CMRF is supposed to perform more accurately in the near future. A second option to circumvent the problem is to restrict the growth of the two parameters γ6 and γ7. If we have knowledge about the values of these two parameters, we can assign then as input to the program and refrain from estimating their values. This will enable us to employ a comparatively non-informative prior which will be easier for the data to overcome. Also, we can use specific bound over those variables while estimating them to avoid them becoming stronger.
Conclusions
Microarray experiments often measure expressions of genes taken from sample tissues in the presence of external perturbations such as medication, radiation, or disease. Typically in such experiments, gene expressions are measured before and after the application of external perturbation.
In this paper, we solved the problem of finding primarily differentially regulated genes in the presence of external perturbations when the data is sampled from two groups. The probabilistic Bayesian method based on Markov Random Field incorporates dependency structure of the gene networks as the prior to the model. Experimental results on synthetic and real datasets demonstrated the superiority of CMRF compared to other simple techniques.
Methods
In this section we describe different components of CMRF. Section Notation and problem formulation describes the notation and formulates the problem. Section Overview of the solution provides a high level overview of the solution. Section Computation of the prior density function describes the calculation of the prior density function of MRF. Section Approximation of the objective function discusses the definition of a tractable objective function. Section Computation of likelihood density function discusses the calculation of the likelihood function. Finally, Section Objective function optimization describes the algorithm to optimize the objective function.
Notation and problem formulation
In this section, we describe our notation and formally define the problem. We define a Bayesian model for gene expression in a two-group perturbation experiment. We classify the random variables of the model into two different groups, namely observed variables and hidden variables. We have the values for the observed variables, while we estimate the values of the hidden variables.
Observed variables
We define two sets of observed variables, one for microarray gene expression data and another for the neighborhood in the extended gene network.
-
Microarray data. We denote the number of genes by M and the number of data points in the two groups D A and D B by N A and N B respectively. We represent the set of genes with . For each gene and for each group the microarray data contains the gene expression values before and after the perturbation, i.e. control and non-control data respectively. We denote the expression value of the ith gene from the jth sample in the control data of group D A with y Aij . We represent the same for the non-control data with . Thus the expression values of the gene g i for all the samples in D A for control and non-control data are and respectively. We denote all the expression values in group D A for gene g i with . We denote the collection of the gene expressions of all the genes in group D A by . We define similarly for all the genes in D B . We refer the complete gene expression data using variable .
-
Neighborhood variables. We use the term to indicate if two genes g i and g j are neighbors in the extended gene network. If g i is an incoming neighbor of g j (i.e. g j has an incoming edge from g i ), then we set the value of W ij (1 ≤ i, j ≤ M) to 1. It is 0 otherwise.
Hidden variables
We define three sets of hidden variables, These variables govern the state of genes, regulations of genes and interactions among genes respectively.
-
State variables. We use and , (1 ≤ i ≤ M) to denote the states of the genes in group D A and D B . S Ai = 1 if g i is DE in D A and 0 if it is EE in D A . We define S Bi similarly. We assume that the metagene g0 is DE for both D A and D B . Thus, S A 0 = S B 0 =1.
-
Regulation variables. We denote the regulation condition of gene g i with Z i . Table 1 enumerates different values of Z i for the values of S Ai and S Bi . In this formulation, the cases Z i = {2, 3} indicate that g i is DR, whereas Z i = {1, 4} indicate that g i is ER. The metagene is guaranteed to be ER, since S A 0 = S B 0 = 1.
-
Interaction variables. In order to govern the joint regulation states of genes g i and g j we define interaction variables . Mathematically, X ij = 4 × (Z i − 1) + Z j . Note that, this equation is created to maintain brevity of the mapping between the interaction variables and the regulation variables by carefully assigning different numeric constants between one and 16 to appropriate values of an interaction variable. Table 1 enumerates different values of X ij for values of Z i and Z j . Specifically, X0j∈ {2, 3} and X0j∈{1, 4} correspond to the cases where g j is DR and ER respectively because of interaction with the metagene g0.
It is easy to see that the hidden variables follow a hierarchical structure. For instance, the value of Z i depends on the values of S Ai and S Bi . Similarly, the value of X ij depends on the values of Z i and Z j . Thus, the value of the dependent variable X ij is based on the values of four independent variables S Ai , S Bi , S Aj and S Bj . Table 1 enumerates the values of Z i , Z j and X ij for different values of S Ai , S Bi , S Aj and S Bj .
It is worth noting that the different values that we assign to the hidden variables are categorical in nature.
Problem formulation
Let denote the set of all genes. Using the definition of the neighborhood variables  , we denote the collection by
, we denote the collection by  which essentially represents the gene networks. We denote the metagene by g0. Given an observed data we want to estimate the probabilities .
which essentially represents the gene networks. We denote the metagene by g0. Given an observed data we want to estimate the probabilities .
A higher value of p (X0j= {2, 3}|·) indicates a higher probability of a gene g j being PDR. Using the estimated values of p (X0j|·), ∀ j ∈ {1, 2,... M}, we can create an ordered list of candidate PDR genes.
Overview of the solution
This section describes a high level overview of our approach to estimate p(X0j|·), ∀ j ∈ {1, 2,... M}. One simple approach can be using a hypothesis test to find out the PDR genes in the given dataset [15]. However, the available hypothesis tests do not consider the interactions among genes in the gene network. Also, deciding on the significance of test can be a complex step. Another approach can be to use SSEM to create a rank of the potential primarily affected genes in each group separately [11]. Then we can select the top k genes in each group and perform a set difference to obtain the PDR genes. Though SSEM considers the correlation between the genes, it does not utilize any known information from the gene networks.
We build a Bayesian probabilistic method based on Markov Random Field where we leverage the information from gene networks as the prior belief of the model. Using Bayes theorem [24] we can write the joint probability density of interaction variables 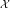 as,
as,
The first term in the numerator, , is the likelihood of the observed expression data  given the interaction variables and gene network. θ
Y
represents the parameters for the likelihood function. A detailed discussion of how we compute this likelihood can be found in Section Computation of likelihood density function. The second term in the numerator represents this prior belief. θ
X
represents the parameters for the prior density function. We define a Markov Random Field (MRF) over the interaction variables and the priors are encoded via feature functions in the MRF. Details of the priors and the associated feature functions are outlined in Section Computation of the prior density function. The denominator of Equation 1 is the normalization constant that represents the sum of the product of the likelihood and the prior over all possible assignments of interaction variables .
given the interaction variables and gene network. θ
Y
represents the parameters for the likelihood function. A detailed discussion of how we compute this likelihood can be found in Section Computation of likelihood density function. The second term in the numerator represents this prior belief. θ
X
represents the parameters for the prior density function. We define a Markov Random Field (MRF) over the interaction variables and the priors are encoded via feature functions in the MRF. Details of the priors and the associated feature functions are outlined in Section Computation of the prior density function. The denominator of Equation 1 is the normalization constant that represents the sum of the product of the likelihood and the prior over all possible assignments of interaction variables .
Given the joint probability density function outlined in Equation 1, our original problem reduces to obtaining assignments for the interaction variables and the parameters θ
X
and θ
Y
that maximize it.
A Maximum Likelihood Estimation (MLE) of Equation 1 is practically infeasible even for a small number of genes since the number of terms in the denominator grows exponentially. Instead we use a pseudo-likelihood version of the objective function as shown in Section Approximation of the objective function. We use Iterative Conditional Modes (ICM) [19] and Differential Evolution [25] in an alternating optimization technique to maximize the pseudo-likelihood with respect to , θ
X
and θ
Y
.
After the optimization, we obtain an assignment for , θ
X
and θ
Y
. Using these assignments and the observed data, we estimate the posterior probability of all X
ij
variables. Using the estimated values of p(X0j|·), ∀
j
∈ {1, 2,... M}, we create an ordered list of candidate PDR genes. We elaborate on each of these steps next.
Figure 2 illustrates different portions of CMRF and the connectivity between them.
Computation of the prior density function
In this section, we describe how we incorporate gene network as the the prior belief into our Bayesian model. From the structure and properties of gene network, we build three hypotheses and embed them into our model. We present the entire concept in three numbered subsections.
1. Statement of hypotheses
Here we state the three hypotheses on the biological networks in brief.
-
Hypothesis 1. In each group D T (T ∈ {A, B}), the metagene g0 can change the state of all the other genes. Thus, all the genes can be directly affected by the external perturbation.
-
Hypothesis 2. In each group D T (T ∈ {A, B}), a gene g i can change the states of its outgoing neighbors g j in the same data group, i.e. a gene can be indirectly affected by the perturbation through genetic interactions.
-
Hypothesis 3. Each gene has a high probability of being equally regulated. This follows from the observation that, often the difference between the expressions of most of the genes in two groups is small. We expect that the response of genes in these groups is very similar.
Clearly, when the data does not follow one or more of the hypotheses, the optimization function can overcome the prior belief with a strong support from the data.
2. Markov Random Field construction
In order to compute the prior density function, we define a Markov Random Field (MRF) over the variables [18]. MRF is a probabilistic model, where the state of a variable depends only on the states of its neighbors. MRF is useful to model our problem as the states of genes depend on their neighbors. Here, the MRF is an undirected graph , where variables represent the vertices of the graph (i.e. each interaction variable X
ij
corresponds to a vertex). We denote the set of edges with . Thus, two variables in share an edge if they share a common subscript at the same position and the two genes corresponding to the other subscript interact in the gene network. For example, in Figure 5(b), X35 and X25 are neighbors, as they share 5 (i.e. gene g5) as the second subscript and g2 and g3 interact in the gene network in Figure 5(a).

A hypothetical gene network and corresponding Markov random graph. (a) A small hypothetical gene network with perturbation in two datasets D A and D B . The genes in the two datasets interact through identical network, although they assume different states. The circle g0 represents the abstraction of the external perturbation. Rectangles denote genes. → implies activation and ⊣ implies inhibition. The potential effect of metagene to all other genes is indicated by dotted arrows from the metagene to all the other genes. For example, g1 is primarily affected in D A , but not affected in D B . g2 is primarily affected in both the datasets. g3 is secondarily affected in both D A and D B . (b) The Markov Random Field graph constructed based on the small hypothetical gene network in (a). The numbers in the parenthesis are the expected assignments to the variables based on the states of the genes in (a). Nodes with dotted boundaries indicate that those nodes are required for completeness of the model, however the corresponding interactions do not exist.
One important point to note is that, this graph does not use the state variables  or the regulation variables
or the regulation variables  to model the dependencies between the genes. Rather, it establishes those dependencies over the variables. For example, in Figure 5(b) we draw the MRF graph corresponding to the hypothetical gene network in Figure 5(a). In the gene network, there is an edge from g2 to g3. So, g2 can potentially change the state of g3. We create an edge from X12 to X13 that corresponds to the edge from g2 to g3. As g1 is common for X12 and X13, if they assume the same value (i.e. X12 = X13), it implies that the genes g2 and g3 are in same state (i.e. S
T
2 = S
T
3,T ∈ {A, B}). We formulate these dependency constraints using a set of unary and binary functions called feature functions. We discuss these feature functions next.
to model the dependencies between the genes. Rather, it establishes those dependencies over the variables. For example, in Figure 5(b) we draw the MRF graph corresponding to the hypothetical gene network in Figure 5(a). In the gene network, there is an edge from g2 to g3. So, g2 can potentially change the state of g3. We create an edge from X12 to X13 that corresponds to the edge from g2 to g3. As g1 is common for X12 and X13, if they assume the same value (i.e. X12 = X13), it implies that the genes g2 and g3 are in same state (i.e. S
T
2 = S
T
3,T ∈ {A, B}). We formulate these dependency constraints using a set of unary and binary functions called feature functions. We discuss these feature functions next.
3. Development of feature functions
We denote the neighbors of X
ij
in the MRF graph as . We define a clique over each X
ij
and its neighbors by C
ij
provided W
ij
= 1. A feature function f(C
ij
) is a Boolean function defined over the clique C
ij
. This function evaluates to one or zero, if it is satisfied or not, respectively. We define a potential function ψ(C
ij
) corresponding to f(C
ij
) as an exponential function given by exp(γf (C
ij
)). Here γ is a coefficient associated with f(C
ij
) that represents the relevance of f(C
ij
) in the MRF. According to Hammersley-Clifford theorem, we express the joint density function of the MRF over as product of potential functions defined over that MRF as, [26]. In this formulation, Δ is the normalization function . To limit the complexity of our model, we consider only cliques of size one and two.
We define seven feature functions to capture the dependencies among the variables in according to the three hypotheses.
Unary feature functions
F1, F2, F3. A primary component of the prior density function is modeling the frequency of X ij itself. Here, we focus on two values of X ij namely X ij = {2, 3}, since they correspond to the events that a gene g j is DR due to the metagene g0. When X ij = 2, g j is DE in D A and EE in D B . To capture this, we define a feature function F1(X ij ) which returns one when X ij = 2. It returns zero otherwise. Similarly, X ij = 3 when g j is EE in D A and DE in D B . We define another feature function F2(X ij ), which returns one when X ij = 3. We capture all the other values of X ij by a feature function called F3(X ij ). It returns zero when X ij ∈ {2, 3} and equals to one otherwise. Table 2 enumerates the the domains and ranges of F1, F2 and F3.
Binary feature functions
F4, F5. Let ϒ represent the hypothesis that in a group D T ,T ∈ {A, B} a gene g j including the metagene can change the state of one of its outgoing neighbors g k . We make a stronger hypothesis ϒ° that, ϒ holds simultaneously in D A and D B with high probability. Note that, this stronger hypothesis is based on the assumption that the genes in both D A and D B express in a similar fashion. This assumption is meaningful as in these two-group perturbation experiments the different groups belong to similar biological conditions [3].
ϒ° is encoded in domain as follows. Consider four genes g
p
, g
i
, g
j
and g
k
, such that g
p
→ g
i
, g
i
→ g
j
and g
j
→ g
k
. Here → indicates that the gene on the left activates or inhibits the gene on the right. By definition, (X
pj
, X
ij
) and (X
ij
, X
ik
) are edges in the MRF. Note that the first edge corresponds to an incoming neighbor g
p
of g
i
, while the second edge corresponds to an outgoing neighbor g
k
of g
j
. We discriminate between these two sets of neighbors of X
ij
, as they are related to the incoming neighbors of g
i
and outgoing neighbors of g
j
respectively. It can be shown that, for the first set of edges, X
pj
equals to X
ij
if and only if (iff) Z
p
= Z
i
, i.e. ϒ° holds true. Similarly, for the second set of edges X
ij
equals to X
ik
iff Z
j
= Z
k
, which in tern implies that ϒ° is satisfied.
We define two sets of feature functions to formalize these equalities based on the incoming neighbors of g i and the outgoing neighbors of g j .
-
Left external equality. We denote the incoming neighbors of g i with In (g i ). We write a feature function f4(X pj , X ij ), ∀ p , g p ∈ In (g i ). f4(X pj , X ij ) = 1 if Z i = Z p and W pi = W ij = 1. Otherwise, f4(X pj , X ij ) = 0. We denote the summation of this function over all the incoming neighbors of g i as,
-
Right external equality. We denote the outgoing neighbors of g j as Out (g j ). We define a feature function f5(X ik , X ij ), ∀ k , g k ∈ Out (g j ). f5 (X ik , X ij ) = 1 if S k = S j and W jk = W ij = 1. Otherwise, f5 (X ik , X ij ) = 0. We denote the summation of this function over all the outgoing neighbors of g j as,
Tables 3 and 4 enumerate the values of f4 and f5 for different values of X ij . The missing entries in these tables correspond to the cases which can not occur during the optimization. For instance, in Table 3, a missing entry corresponds to different values of Z j in X ij and X pj which is not possible.
For feature functions f4 and f5, X pj or X ik may not represent any interactions from the extended gene network when W pj = 0 or W ik = 0 respectively. We represent them by dotted rectangles in Figure 5(b).
Unary feature functions
F6, F7. We introduce two unary feature functions to incorporate our last hypothesis, that all genes are ER with a high probability. We consider two genes g i and g j such that g i → g j . This hypothesis holds true, if g i is equally regulated or g j is equally regulated.
-
Left internal equality. We define this feature function to capture the events when g i is equally regulated. As, g j can assume any state, this feature function holds true for eight different values of X ij . We denote the feature function by f6(X ij , t) that returns one if its two arguments are equal and zero otherwise. We denote the summation of this functions over all these eight values of X ij as,
-
Right internal equality. We define this feature function to capture the events when g j is equally regulated. As, g i can assume any state, this feature function holds true for eight different values of X ij . We denote the feature function by f7(X ij , t) that returns one if its two arguments are equal and zero otherwise. We denote the summation of this functions over all these eight values of X ij as,
The last two columns of Table 2 enumerate these two internal equalities.
Based on these feature functions, we define the joint density function of as,
In the above equation γ k , k ∈ {1, 2,... 7} are the coefficients of the seven feature functions in MRF.
In the next section, we discuss how we approximate the objective function of the MRF and the data. We also describe how we formulate the posterior probability density function for X ij .
Approximation of the objective function
A direct maximization of the objective function given by Equation 1 is intractable, as it requires evaluation of exponential number of terms in the denominator. We employ pseudo-likelihood as an established substitute to Equation 1 [27]. Pseudo-likelihood is the simple product of the conditional probability density function of the X ij variables. Geman et al. proved the consistency of the maximum pseudo-likelihood estimate [28]. The approximated objective function can be written as,
The posterior density function F ij of X ij as,
Derivation of F ij .
In step 2 of the derivation, we substitute  by Y
Ai
, Y
Bi
, Y
Aj
and Y
Bj
as X
ij
is independent of all Y
Ck
such that k ≠ {i, j} and C ≠ {A, B}. Also, in the 15th step we assume that X
ij
is independent of θ
Y
given and θ
X
. □
by Y
Ai
, Y
Bi
, Y
Aj
and Y
Bj
as X
ij
is independent of all Y
Ck
such that k ≠ {i, j} and C ≠ {A, B}. Also, in the 15th step we assume that X
ij
is independent of θ
Y
given and θ
X
. □
Derivation of , W ij = 1.
A (X ij ) is and B(ij) is given by . Here, we denote the prior density parameters {γ1, γ2,...·γ7} by θ X . Canceling B(ij) from numerator and denominator the density function simplifies to,
□
There are two different terms in objective function of Equation 4. stands for the conditional prior density function of X ij which we just have derived from using Bayes rule. In the next section, we discuss the likelihood function .
Computation of likelihood density function
In this section, we describe how we derive the likelihood function in three numbered subsections. Here, we assume that gene expressions in a group follow a normal distribution, We can rewrite the derivations if gene expressions follow some other distribution.
1. Likelihood for a single gene
Consider a set of measurements for a gene g i that follows a single Gaussian distribution by z i = {z i 1, z i 2,..., z iN }. We denote the latent mean of z i as µ and the standard deviation as σ. As different genes can have different average expressions, we assume that µ follows a genome wise distribution with mean µ0 and standard deviation τ [29]. Thus, for z i , the likelihood for the data points in that group is given by,
The derivation of Equation 5 can be obtained from Demichelis et al [30]. If a gene is DE, its expression measurements in control and non-control groups follow different distributions [29]. On the other hand, for equally expressed genes, all the measurements in both groups share the same mean. The likelihood function for a DE gene g i in group D T ,T ∈ {A, B} is given by,
Similarly, for EE genes it is given by,
For instance, the likelihood of a gene to be DE in group D A is given by .
2. Likelihood for a regulation variable
As for a gene g i , the regulation variable Z i can assume four different values from 1 to 4, the equations of the likelihood that a gene is DR or ER also take four different forms given by,
2. Likelihood for an interaction variable
We have 16 different forms for the likelihood of the X ij due to its 16 different values. However, here, we shall derive only for X ij = 1, as for the other values of X ij we have a similar derivation.
From the definition of equals to 1 when Z i = 1 and Z j = 1. Its value is zero for all other values of Z i and Z j . So, continuing from the last step of Equation 8,
In a similar way, we can derive the likelihood functions for all the 16 different values of X ij variables. A special case arises when g i is the metagene, i.e. g0. We assume that and . Thus, the likelihood of the metagene given Z0 = 1 equals to 1. Its value is zero otherwise.
Objective function optimization
So far, we have described how we compute the posterior density function. The final challenge is to find the values of the hidden variables that maximize the objective function (Equation 3). We develop an iterative algorithm to address this challenge.
In our model we have three different sets of parameters. The nodes of the MRF given by consist of one set. Other two sets are the parameters of conditional probability density function of X
ij
and likelihood function of observed data given by θ
X
= {γ1,... γ7} and θ
Y
= {µ0, σ, τ), respectively. In each iteration, we first estimate θ
X
and θ
Y
based on the estimated value of in the previous iteration. Next, based on the estimated parameters, we estimate that maximize the objective function in Equation 3.
The likelihood function is non-convex in terms of the parameters θ Y = {µ0, σ, τ). Also, the conditional density is non-convex in terms of θ X = {γ1,... γ7}. We use a global optimization method called differential evolution to optimize both of them [25]. To optimize the objective function in Equation 3, we employ the ICM algorithm described by Besag [19]. Briefly, our iterative algorithm works as follows.
-
1.
Obtain an initial estimate of
 variables. In our implementation we use student's t-test assuming the data follows normal distribution. We use 5% confidence interval for this purpose.
variables. In our implementation we use student's t-test assuming the data follows normal distribution. We use 5% confidence interval for this purpose. -
2.
Estimate parameters θ Y that maximizes the data likelihood function given by,
We implement this step using Differential Evolution, which is similar to the genetic algorithm.
 variables. In our implementation we use student's t-test assuming the data follows normal distribution. We use 5% confidence interval for this purpose.
variables. In our implementation we use student's t-test assuming the data follows normal distribution. We use 5% confidence interval for this purpose.-
3.
Calculate an estimate of the parameters θ X that maximizes the conditional prior density function by,
We also implement this step using Differential Evolution.
-
4.
Carry out a single cycle of ICM using the current estimate of
 , θ
X
and θ
Y
. For all S
i
, maximize when .
, θ
X
and θ
Y
. For all S
i
, maximize when . -
5.
Go to step 2 for a fixed number of cycles or until
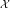 converges to a certain predefined value.
converges to a certain predefined value.
 , θ
X
and θ
Y
. For all S
i
, maximize when .
, θ
X
and θ
Y
. For all S
i
, maximize when .We optimize the objective function in terms of the S i (1 ≤ i ≤ M) variables instead of X ij variables. Specifically, in step 4, we go over all the S i variables, and optimize F ij function (given by Equation 4) for only those X ij variables that are impacted by the change of S i . Figure 2 illustrates different components of CMRF and the connectivity between them.
The optimization procedure is guaranteed to converge since in every iteration the value of the objective function increases. We continue the iterative process, until the changes in estimates of the parameters between two consecutive iterations reach below a certain cutoff level.
References
Cheng R, Zhao A, Alvord W, Powell D, Bare R, Masuda A, Takahashi T, Anderson L, Kasprzak K: Gene expression dose-response changes in microarrays after exposure of human peripheral lung epithelial cells to nickel(II). Toxicol Appl Pharmacol. 2003, 191: 22-39. 10.1016/S0041-008X(03)00228-X.
Ideker T, Thorsson V, Ranish J, Christmas R, Buhler J, Eng J, Bumgarner R, Goodlett D, Aebersold R, Hood L: Integrated genomic and proteomic analyses of a systematically perturbed metabolic network. Science. 2001, 292 (5518): 929-34. 10.1126/science.292.5518.929.
Taylor K, Pena-Hernandez K, Davis J, Arthur G, Duff D, Shi H, Rahmatpanah F, Sjahputera O, Caldwell C: Large-scale CpG methylation analysis identifies novel candidate genes and reveals methylation hotspots in acute lymphoblastic leukemia. Cancer Res. 2007, 67 (6): 2617-25. 10.1158/0008-5472.CAN-06-3993.
Hughes TR, Marton MJ, Jones AR, Roberts CJ, Stoughton R, Armour CD, Bennett HA, Coffey E, Dai H, He YD, Kidd MJ, King AM, Meyer MR, Slade D, Lum PY, Stepaniants SB, Shoemaker DD, Gachotte D, Chakraburtty K, Simon J, Bard M, Friend SH: Functional discovery via a compendium of expression profiles. Cell. 2000, 102: 109-126. 10.1016/S0092-8674(00)00015-5.
Marton MJ, Derisi JL, Bennett HA, Iyer VR, Meyer MR, Roberts CJ, Stoughton R, Burchard J, Slade D, Dai H, Bassett DE, Hartwell LH, Brown PO, Friend SH: Drug target validation and identification of secondary drug target effects using DNA microarrays. Nat Med. 1998, 4 (11): 1293-1301. 10.1038/3282.
Giaever G, Shoemaker DD, Jones TW, Liang H, Winzeler EA, Astromoff A, Davis RW: Genomic profiling of drug sensitivities via induced haploinsufficiency. Nature Genetics. 1999, 21 (3): 278-283. 10.1038/6791.
Giaever G, Flaherty P, Kumm J, Proctor M, Nislow C, Jaramillo DF, Chu AM, Jordan MI, Arkin AP, Davis RW: Chemogenomic profiling: Identifying the functional interactions of small molecules in yeast. Proceedings of the National Academy of Sciences of the United States of America. 2004, 101 (3): 793-798. 10.1073/pnas.0307490100.
Lum P, Armour C, Stepaniants S, Cavet G, Wolf M, Butler J, Hinshaw J, Garnier P, Prestwich G, Leonardson A, Garrett-Engele P, Rush C, Bard M, Schimmack G, Phillips J, Roberts C, Shoemaker D: Discovering modes of action for therapeutic compounds using a genome-wide screen of yeast heterozygotes. Cell. 2004, 116: 121-37. 10.1016/S0092-8674(03)01035-3.
Parsons AB, Brost RL, Ding H, Li Z, Zhang C, Sheikh B, Brown GW, Kane PM, Hughes TR, Boone C: Integration of chemical-genetic and genetic interaction data links bioactive compounds to cellular target pathways. Nature Biotechnology. 2003, 22: 62-69.
di Bernardo D, Thompson MJ, Gardner TS, Chobot SE, Eastwood EL, Wojtovich AP, Elliott SJ, Schaus SE, Collins JJ: Chemogenomic profiling on a genome-wide scale using reverse-engineered gene networks. Nature Biotechnology. 2005, 23 (3): 377-383. 10.1038/nbt1075.
Cosgrove EJ, Zhou Y, Gardner TS, Kolaczyk ED: Predicting gene targets of perturbations via network-based filtering of mRNA expression compendia. Bioinformatics. 2008, 24 (21): 2482-2490. 10.1093/bioinformatics/btn476.
Bandyopadhyay N, Somaiya M, Kahveci T, Ranka S: Modeling perturbations using gene networks. Proc LSS Comput Syst Bioinform Conf. 2010, 26-37.
Conesa A, Nueda MJ, Ferrer A, Talón M: maSigPro: a method to identify significantly differential expression profiles in time-course microarray experiments. Bioinformatics. 2006, 22 (9): 1096-1102. 10.1093/bioinformatics/btl056.
Hong F, Li H: Functional Hierarchical Models for Identifying Genes with Different Time-Course Expression Profiles. Biometrics. 2006, 62 (2): 534-544. 10.1111/j.1541-0420.2005.00505.x.
Chuan Tai Y, Speed TP: On Gene Ranking Using Replicated Microarray Time Course Data. Biometrics. 2009, 65: 40-51. 10.1111/j.1541-0420.2008.01057.x.
Angelini C, De Canditiis D, Pensky M: Bayesian models for two-sample time-course microarray experiments. Computational Statistics & Data Analysis. 2009, 53 (5): 1547-1565. 10.1016/j.csda.2008.07.015.
Van Deun K, Hoijtink H, Thorrez L, Van Lommel L, Schuit F, Van Mechelen I: Testing the hypothesis of tissue selectivity: the intersection-union test and a Bayesian approach. Bioinformatics. 2009, 25 (19): 2588-2594. 10.1093/bioinformatics/btp439.
Li SZ: Markov Random Field Modeling in Image Analysis. 2009, Springer Publishing Company, Incorporated, 3
Besag J: On the statistical analysis of dirty pictures. Journal of the Royal Statistical Society. 1986, 48 (3): 259-302.
Smirnov D, Morley M, Shin E, Spielman R, Cheung V: Genetic analysis of radiation-induced changes in human gene expression. Nature. 2009, 459 (7246): 587-91. 10.1038/nature07940.
Dausset J, Cann H, Cohen D, Lathrop M, Lalouel J, White R: Centre d'etude du polymorphisme humain (CEPH): collaborative genetic mapping of the human genome. Genomics. 1990, 6 (3): 575-7. 10.1016/0888-7543(90)90491-C.
Garg A, Mendoza L, Xenarios I, DeMicheli G: Modeling of multiple valued gene regulatory networks. Conf Proc IEEE Eng Med Biol Soc. 2007, 2007: 1398-404.
Kanehisa M, Goto S: KEGG: kyoto encyclopedia of genes and genomes. Nucleic Acids Res. 2000, 28: 27-30. 10.1093/nar/28.1.27.
Bishop CM: Pattern Recognition and Machine Learning (Information Science and Statistics). 2006, Secaucus, NJ, USA: Springer-Verlag New York, Inc
Storn R, Price K: Differential evolution — a simple and efficient heuristic for global optimization over continuous spaces. Journal of Global Optimization. 1997, 11 (4): 341-359. 10.1023/A:1008202821328.
Hammersley JM, Clifford P: Markov fields on finite graphs and lattices. Unpublished manuscript. 1968
Besag J: Efficiency of pseudolikelihood estimation for simple Gaussian fields. Biometrika. 1977, 64 (3): 616-618. 10.1093/biomet/64.3.616.
Geman S, Graffigne C: Markov random field image models and their applications to computer vision. Proceedings of the International Congress of Mathematics: Berkley. 1986, 1496-1517.
Kendziorski C, Newton M, Lan H, Gould M: On parametric empirical Bayes methods for comparing multiple groups using replicated gene expression profiles. Stat Med. 2003, 22 (24): 3899-914. 10.1002/sim.1548.
Demichelis F, Magni P, Piergiorgi P, Rubin M, Bellazzi R: A hierarchical Naive Bayes Model for handling sample heterogeneity in classification problems: an application to tissue microarrays. BMC Bioinformatics. 2006, 7: 514-10.1186/1471-2105-7-514.
Acknowledgements
This work was supported partially by NSF under grants CCF-0829867 and IIS-0845439.
This article has been published as part of BMC Genomics Volume 13 Supplement 2, 2012: Selected articles from the First IEEE International Conference on Computational Advances in Bio and medical Sciences (ICCABS 2011): Genomics. The full contents of the supplement are available online at http://www.biomedcentral.com/bmcgenomics/supplements/13/S2.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors' contributions
NB conceived the study, analyzed the data, implemented the methods, supplied the analysis tools, designed the experiments, performed the experiments and wrote the paper. MS conceived the study and participated in writing the paper. SR conceived the study, designed the experiments and participated in writing the paper. TK conceived the study, designed the experiments and participated in writing the paper.
Rights and permissions
This article is published under license to BioMed Central Ltd. This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Bandyopadhyay, N., Somaiya, M., Ranka, S. et al. CMRF: analyzing differential gene regulation in two group perturbation experiments. BMC Genomics 13 (Suppl 2), S2 (2012). https://doi.org/10.1186/1471-2164-13-S2-S2
Published:
DOI: https://doi.org/10.1186/1471-2164-13-S2-S2